19. Jan. 2026
Warum die meisten RAG-Systeme unsicher sind und wie Sie ein sicheres aufbauen
Erkenntnisse aus echten Datenlecks und wie Sie RAG-Systeme so entwerfen, dass sie solche Fehler vermeiden.

Martin Paloncy
Partnership Manager


Erkenntnisse aus echten Datenlecks und wie Sie RAG-Systeme so entwerfen, dass sie solche Fehler vermeiden.
Martin Paloncy
Partnership Manager
Im Jahr 2023, nur Wochen nachdem Samsung seinen Mitarbeitern die Nutzung von ChatGPT erlaubt hatte, kam es innerhalb eines Monats zu mehreren Datenlecks. Um schneller voranzukommen, fügten Entwickler vertraulichen Quellcode in den Chatbot ein und baten um „Optimierung“. Andere luden Besprechungsaufzeichnungen hoch, damit das KI-Modell Protokolle erstellte.
ChatGPT speicherte Eingaben damals automatisch für das Training. Samsungs proprietärer Halbleiter-Designs und interne Besprechungsprotokolle wurden so faktisch Teil der Trainingsdaten von OpenAI. In einem anderen Fall gaben Amazon-Juristen laut Business Insider sogar an, KI-Ausgaben gesehen zu haben, die internen Unternehmensdaten stark ähnelten.
Unabhängig von den Richtlinien zur Datenspeicherung verarbeiten derzeit alle großen KI-Dienste Prompts im Klartext und legen sensible Eingaben gegenüber den Administratoren von Cloud und KI-Dienst offen. In einer Zeit, in der Daten bei Speicherung und Übertragung standardmäßig verschlüsselt sind, ist das für sicherheitsbewusste Nutzer inakzeptabel und ein wesentlicher Grund für die geringe Verbreitung von RAG in Branchen wie dem Gesundheitswesen oder der öffentlichen Verwaltung. Um diese Offenlegung zu begrenzen, haben sich zwei Lösungen herausgebildet: Entweder Sie verarbeiten Ihre Daten im Klartext, aber nicht in der Cloud. Oder Sie verarbeiten sie in der Cloud, aber nicht im Klartext. Diese Ansätze schließen sich nicht gegenseitig aus. In diesem Beitrag teile ich meine Erfahrungen und Best Practices, um das Beste aus beiden Welten zu vereinen.
Retrieval Augmented Generation (RAG) ist eine Technik, um die Qualität von KI-Antworten bei Fragen zu spezifischen Informationen zu verbessern, indem dem Prompt zusätzlicher Kontext hinzugefügt wird („Anreicherung“). Statt sich nur auf die Trainingsdaten des Modells zu verlassen (die für die meisten allgemeinen Fragen ausreichen), werden dem Modell eigene, oft unternehmensspezifische Informationen als Kontext bereitgestellt.
Was das Modell sieht
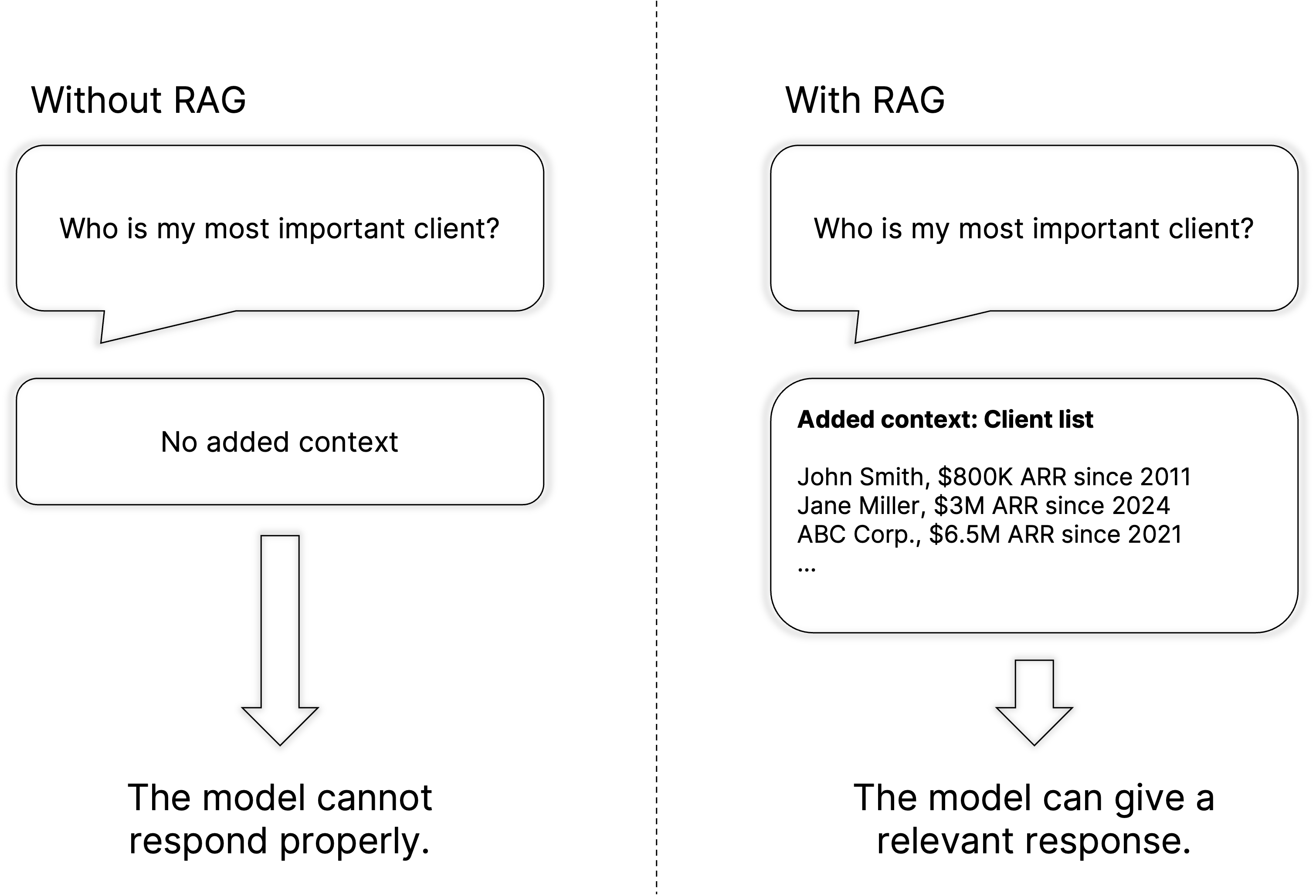
Je mehr relevante Daten Ihr RAG-System nutzen kann, desto wertvoller ist es für Sie. Und ja, die Relevanz Ihrer Daten korreliert oft mit ihrer Sensibilität. RAG, das die Produktivität spürbar steigert, benötigt Zugriff auf Ihr internes Wissen, insbesondere auf die vertraulichen Teile.
Ohne geeignete Sicherheitsvorkehrungen kann das katastrophale Datenlecks verursachen, Mitarbeitern schaden und sogar Dritten wie Kunden und Partnern Schaden zufügen. Datensicherheit verdient daher an zwei Stellen besondere Aufmerksamkeit: bei der Ingestion (dem Einspeisen von Informationen in das System) und beim Retrieval (dem Stellen von Fragen an das System).
Ingestion ist der Prozess, Dokumente und andere Daten in Formate zu überführen, die ein LLM durchsuchen und lesen kann. Gängige Ansätze sind Vektordatenbanken und Wissensgraphen.
Sie können das eine, das andere oder beides als Grundlage Ihrer Wissensbasis nutzen. Beide Ansätze erfordern in der Regel KI-Inferenz während der Ingestion.
Um semantische Informationen als Vektor abzubilden, benötigen Sie ein Embedding-Modell. Embedding-Modelle teilen Ihre Dokumente in Chunks auf und weisen ihnen Vektorwerte zu. Diese lassen sich mit Ihren Prompts vergleichen, um semantische Ähnlichkeiten und damit die relevantesten Datenquellen für Ihre Anfrage zu finden.
Privatemode AI bietet eine vertrauliche Embedding-API. Für Tests und den persönlichen Gebrauch empfehle ich jedoch, ein Embedding-Modell zu wählen und es lokal auszuführen. Aus zwei Gründen:
Die Privatemode Embedding-API ist für größere Systeme nützlich. Nutzen Sie sie statt eines lokalen Modells, wenn:
On-Premises-KI-Plattformen wie Zylon.ai bieten lokale Embedding- und SLM-Funktionen sowie eine Anbindung an die sicheren und leistungsstarken LLMs von Privatemode für den Zugriff auf Reasoning-Modelle. Das ermöglicht einfache Orchestrierung und flexibles Testen für Ihre konkreten Anwendungsfälle, ohne Daten offenzulegen.
Wissensgraphen sind im Grunde maschinenlesbare Mindmaps, die Entitäten wie Organisationen, Personen, Orte usw. und die Beziehungen zwischen ihnen beschreiben. Sie erweisen sich als äußerst nützlich für das Context Engineering und liefern Ihrem LLM relevante Zusatzinformationen, auch wenn diese Ihrem Prompt semantisch nicht ähneln.
Beim Einlesen von Dokumenten in einen Wissensgraphen können Reasoning-LLMs diese Entitäten und Beziehungen zuverlässig extrahieren („Jane Doe <> WORKS_AT <> Doe Corp.“). Dafür muss das LLM jedoch das gesamte (sensible) Dokument lesen. Genau hier wird Privatemode AI für alle nützlich und für manche notwendig.
Reasoning-LLMs, die „klug“ genug sind, um Entitäten korrekt zu erkennen und zueinander in Beziehung zu setzen, laufen nicht effizient auf Laptops oder selbst leistungsstarken PCs. Sie benötigen Server-Hardware oder persönliche Supercomputer, was die Vertraulichkeit der Daten zur echten Herausforderung macht. Privatemode AI bietet Ihnen einen Weg, auf gpt-oss-120b und (bald) weitere Reasoning-Modelle zuzugreifen, ohne den Datenschutz zu opfern. Niemand kann Eingaben jemals im Klartext sehen, weder Cloud- noch Dienstanbieter. So lassen sich Ihre sensiblen Dokumente sicher in einen (lokalen) Wissensgraphen einlesen.
Retrieval ist der Prozess, über eine semantische Suche relevanten Kontext für Ihren Prompt oder Ihre Frage zu sammeln. Ähnlich wie bei der Ingestion ist für die meisten Nutzer ein hybrider Ansatz aus lokalen Modellen und vertraulicher Cloud-Inferenz am besten:
Zuerst sollte Ihr Prompt vom selben lokalen Embedding-Modell in Vektoren umgewandelt werden. Diese Vektoren werden mit den gespeicherten Vektoren in Ihrer Datenbank abgeglichen. Zusätzlich kann eine Suche über Ihren Wissensgraphen erfolgen, um verwandte Informationen abzudecken, die semantisch nicht passen. Anschließend können lokal laufende Small Language Models („SLMs“) den abgerufenen Kontext zu einem kohärenten „Master-Prompt“ zusammenfassen. Das lässt sich lokal erledigen, da SLMs für solche Aufgaben inzwischen leistungsfähig genug sind und die Latenz minimieren.
Hinweis: Bei lokalen SLMs und Embedding-Modellen kann es sich lohnen, alternative Architekturen zu Transformer-Modellen in Betracht zu ziehen, etwa Liquid Foundational Models (LFMs). In der Regel übertreffen sie GPT-SLMs mit bis zu 1 Milliarde Parametern.
Schließlich kann der angereicherte Prompt mit dem gesamten relevanten Kontext in passender Struktur über Privatemode AI an Ihr Reasoning-Modell geschickt werden, für die eigentliche Schwerstarbeit: das rechenintensive Reasoning, das ein großes Modell erfordert. Hier möchten Sie das leistungsfähigste Modell mit ausreichendem Kontextfenster, sodass eine rein lokale Lösung für die meisten Nutzer nicht praktikabel ist.
Was bedeutet das für Sie? Setzen Sie auf lokale Embedding-Modelle für standardisierte, private Vektor-Indizierung, auf lokale SLMs für schnelles, privates Anreichern von Prompts und auf Privatemode AI für anspruchsvolles, aber vertrauliches Reasoning.
Überprüfen Sie noch heute Ihre KI-Infrastruktur und stellen Sie sicher, dass Ihre Pipelines Daten durchgehend schützen. Und schauen Sie sich Privatemode AI an, um die Leistung fortschrittlicher Modelle zu nutzen, ohne beim Datenschutz Abstriche zu machen.
Die Zukunft der KI ist hybrid, und wer heute beginnt, ist der Entwicklung weiterhin voraus.

Wie sich LLMs produktiv nutzen lassen, ohne dass Anbieter Zugriff auf die Daten haben – Confidential Computing und die passende Verschwiegenheitsvereinbarung nach § 203 StGB.

Apple Private Cloud Compute läuft nun auf Hardware von Drittanbietern. Während Confidential AI zum Standard für private Inferenz auf weitverbreiteter Rechenzentrums-Hardware wird, rückt die eigentliche Frage in den Vordergrund: transparente Verifizierbarkeit.